Elasticsearch Mesos Framework
Roadmap
Features
- Deployment ✓
- Durable cluster topology (via ZooKeeper) ✓
- Web UI on scheduler port 31100 ✓
- Support deploying multiple Elasticsearch clusters to single Mesos cluster ✓
- Fault tolerance ✓
- Customised ES configuration ✓
- Configurable data directory ✓
- Scale cluster horizontally ✓
- Snapshot and restore ✓
[Future]
- High availability (master, indexer, replica)
- Upgrading configuration
- Scale cluster vertically
- Upgrade
- Rollback
Blocked features
Developer Tools
- Local environment (Docker-machine) ✓
- Rapid code + test (Mini Mesos) ✓
- Build automation (Gradle and Jenkins) ✓
User tools
- One JSON post to marathon install ✓
Getting Started
We recommend that users install via marathon, using a docker container.
This framework requires:
- A running Mesos cluster on version 0.25.0
- The use of Marathon is strongly recommended to provide resiliency against scheduler failover.
- That the slaves have routable IP addresses. The ES ports are exposed on the slaves, so that the ES cluster can discover each other. Please double check that your slaves are routable.
Users Guide
Mesos version support
The framework currently supports Mesos 0.25.0. It may work with newer or older versions of Mesos, but the tests are only performed on this version.
How to install on Marathon
Create a Marathon file like the one below and fill in the IP addresses and other configuration. This is the minimum viable command; there are many more options.
{
"id": "elasticsearch,
"container": {
"docker": {
"image": "mesos/elasticsearch-scheduler",
"network": "HOST"
}
},
"args": ["--zookeeperMesosUrl", "zk://ZOOKEEPER_IP_ADDRESS:2181/mesos"],
"cpus": 0.2,
"mem": 512.0,
"env": {
"JAVA_OPTS": "-Xms128m -Xmx256m"
},
"instances": 1
}
Then post to marathon to instantiate the scheduler:
curl -k -XPOST -d @marathon.json -H "Content-Type: application/json" http://MARATHON_IP_ADDRESS:8080/v2/apps
Note: the JAVA_OPTS line is required. If this is not set, then the Java heap space will be incorrectly set.
Other command line options include:
Usage: (Options preceded by an asterisk are required) [options]
Options:
--dataDir
The host data directory used by Docker volumes in the executors. [DOCKER
MODE ONLY]
Default: /var/lib/mesos/slave/elasticsearch
--elasticsearchBinaryUrl
The elasticsearch binary to use (Must be tar.gz format). E.g. 'https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.2.0/elasticsearch-2.2.0.tar.gz'
[JAR MODE ONLY]
Default: <empty string>
--elasticsearchClusterName
Name of the elasticsearch cluster
Default: mesos-ha
--elasticsearchCpu
The amount of CPU resource to allocate to the elasticsearch instance.
Default: 1.0
--elasticsearchDisk
The amount of Disk resource to allocate to the elasticsearch instance
(MB).
Default: 1024.0
--elasticsearchDockerImage
The elasticsearch docker image to use. E.g. 'elasticsearch:latest'
[DOCKER MODE ONLY]
Default: elasticsearch:latest
--elasticsearchExecutorCpu
The amount of CPU resource to allocate to the elasticsearch executor.
Default: 0.1
--elasticsearchExecutorRam
The amount of ram resource to allocate to the elasticsearch executor
(MB).
Default: 32.0
--elasticsearchNodes
Number of elasticsearch instances.
Default: 3
--elasticsearchPorts
User specified ES HTTP and transport ports. [NOT RECOMMENDED]
Default: <empty string>
--elasticsearchRam
The amount of ram resource to allocate to the elasticsearch instance
(MB).
Default: 256.0
--elasticsearchSettingsLocation
Path or URL to ES yml settings file. Path example:
'/var/lib/mesos/config/elasticsearch.yml'. URL example: 'https://gist.githubusercontent.com/mmaloney/5e1da5daa58b70a3a671/raw/elasticsearch.yml'.
In Docker mode a volume will be created from /tmp/config in the container to
the directory that contains elasticsearch.yml.
Default: <empty string>
--executorForcePullImage
Option to force pull the executor image. [DOCKER MODE ONLY]
Default: false
--executorName
The name given to the executor task.
Default: elasticsearch-executor
--externalVolumeDriver
This defines the use of an external storage drivers to be used. By
default, elasticsearch nodes will not be created with external volumes but rather
direct attached storage.
Default: <empty string>
--externalVolumeOptions
This describes how volumes are to be created.
Default: <empty string>
--frameworkFailoverTimeout
The time before Mesos kills a scheduler and tasks if it has not recovered
(ms).
Default: 2592000.0
--frameworkName
The name given to the framework.
Default: elasticsearch
--frameworkPrincipal
The principal to use when registering the framework (username).
Default: <empty string>
--frameworkRole
Used to group frameworks for allocation decisions, depending on the
allocation policy being used.
Default: *
--frameworkSecretPath
The path to the file which contains the secret for the principal
(password). Password in file must not have a newline.
Default: <empty string>
--frameworkUseDocker
The framework will use docker if true, or jar files if false. If false,
the user must ensure that the scheduler jar is available to all slaves.
Default: true
--javaHome
When starting in jar mode, if java is not on the path, you can specify
the path here. [JAR MODE ONLY]
Default: <empty string>
--useIpAddress
If true, the framework will resolve the local ip address. If false, it
uses the hostname.
Default: false
--webUiPort
TCP port for web ui interface.
Default: 31100
--zookeeperMesosTimeout
The timeout for connecting to zookeeper for Mesos (ms).
Default: 20000
* --zookeeperMesosUrl
Zookeeper urls for Mesos in the format zk://IP:PORT,IP:PORT,...)
Default: zk://mesos.master:2181
Framework Authorization
To use framework Auth, and if you are using docker, you must mount a docker volume that contains your secret file. You can achieve this by passing volume options to marathon. For example, if you wanted to use the file located at /etc/mesos/frameworkpasswd, then could use the following:
...
"docker": {
"image": "mesos/elasticsearch-scheduler",
"network": "HOST"
},
"volumes": [
{
"containerPath": "/etc/mesos/frameworkpasswd",
"hostPath": "/etc/mesos/frameworkpasswd",
"mode": "RO"
}
]
},
...
Please note that the framework password file must only contain the password (no username) and must not have a newline at the end of the file. (Marathon bugs)
Using JAR files instead of docker images
It is strongly recommended that you use the containerized version of Mesos Elasticsearch. This ensures that all dependencies are met. Limited support is available for the jar version, since many issues are due to OS configuration. However, if you can't or don't want to use containers, use the raw JAR files in the following way: 1. Requirements: Java 8, Apache Mesos. 2. Set the CLI parameter frameworkUseDocker to false. Set the javaHome CLI parameter if necessary. 3. Run the jar file manually, or use marathon. Normal command line parameters apply. For example:
{
"id": "elasticsearch",
"cpus": 0.2,
"mem": 512,
"instances": 1,
"cmd": "java -jar scheduler-1.0.0.jar --frameworkUseDocker false --zookeeperMesosUrl zk://10.0.0.254:2181 --frameworkName elasticsearch --elasticsearchClusterName mesos-elasticsearch --elasticsearchCpu 1 --elasticsearchRam 1024 --elasticsearchDisk 1024 --elasticsearchNodes 3 --elasticsearchSettingsLocation /home/ubuntu/elasticsearch.yml",
"uris": [ "https://github.com/mesos/elasticsearch/releases/download/1.0.0/scheduler-1.0.0.jar" ],
"env": {
"JAVA_OPTS": "-Xms256m -Xmx512m"
},
"ports": [31100],
"requirePorts": true,
"healthChecks": [
{
"gracePeriodSeconds": 120,
"intervalSeconds": 10,
"maxConsecutiveFailures": 6,
"path": "/",
"portIndex": 0,
"protocol": "HTTP",
"timeoutSeconds": 5
}
]
}
Jars are available under the (releases section of github)[https://github.com/mesos/elasticsearch/releases].
External volumes
The elasticsearch database can be given a third layer of data resiliency (in addition to sharding, and replication) by using exernal volumes. External volumes are storage devices that are mounted externally to the application. For example, AWS's EBS volumes. To enable this feature, simply specify the docker volume plugin that you wish to use. For example: --externalVolumeDriver rexray. This will create volumes prefixed with the framework name and a numeric ID of the node, e.g. elasticsearch0data. Volume options can be passed using the --externalVolumeOptions parameter.
The most difficult part is setting up a docker volume plugin. The next few sections will describe how to setup the "rexray" docker volume plugin.
Docker mode installation of the rexray docker volume plugin
In docker mode, the applications rexray and dvdcli: https://github.com/emccode/rexray https://github.com/emccode/dvdcli
Below is a script that will install these applications for you on AWS. Ensure the following AWS credentials are exported on your host: $TF_VAR_access_key, $TF_VAR_access_key. To use, simply run the script with an argument pointing to an agent. E.g. ./installRexray.sh url.or.ip.to.agent.
Then to use external volumes, simply pass the required argument. Below is an example marathon json:
{
"id": "es-rexray",
"cpus": 1.0,
"mem": 512,
"instances": 1,
"args": [
"--zookeeperMesosUrl", "zk://$MASTER:2181/mesos",
"--elasticsearchCpu", "0.5",
"--elasticsearchRam", "1024",
"--elasticsearchDisk", "1024",
"--externalVolumeDriver", "rexray"
],
"env": {
"JAVA_OPTS": "-Xms32m -Xmx256m"
},
"container": {
"type": "DOCKER",
"docker": {
"image": "mesos/elasticsearch-scheduler:latest",
"network": "HOST",
"forcePullImage": true
}
},
"ports": [31100],
"requirePorts": true
}
Jar mode installation of the rexray docker volume plugin
It is possible to use in jar mode using the mesos-module-dvdi project, or the mesos-flocker project. Testing has been performed with the mesos-module-dvdi project. https://github.com/emccode/mesos-module-dvdi https://github.com/ClusterHQ/mesos-module-flocker
The following script (in addition to the previous docker script) will install the required software. To use, simply run the script with an argument pointing to an agent. E.g. ./installRexrayLib.sh url.or.ip.to.agent.
Data directory
The ES node data can be written to a specific directory. If in docker mode, use the --dataDir option. If in jar mode, set the path.data option in your custom ES settings file.
The cluster name and slaveID will be appended to the end of the data directory option. This allows users with a shared network drive to write node specific data to their own seperate location.
For example, if the user specifies a data directory of /var/lib/data, then the data for the agent with a Slave ID of S1 will be written to /var/lib/data/mesos-ha/S1.
User Interface
The web based user interface is available on port 31100 of the scheduler by default. It displays real time information about the tasks running in the cluster and a basic configuration overview of the cluster.
The user interface uses REST API of the Elasticsearch Mesos Framework. You can find the API documentation here: docs.elasticsearchmesos.apiary.io.
Cluster Overview
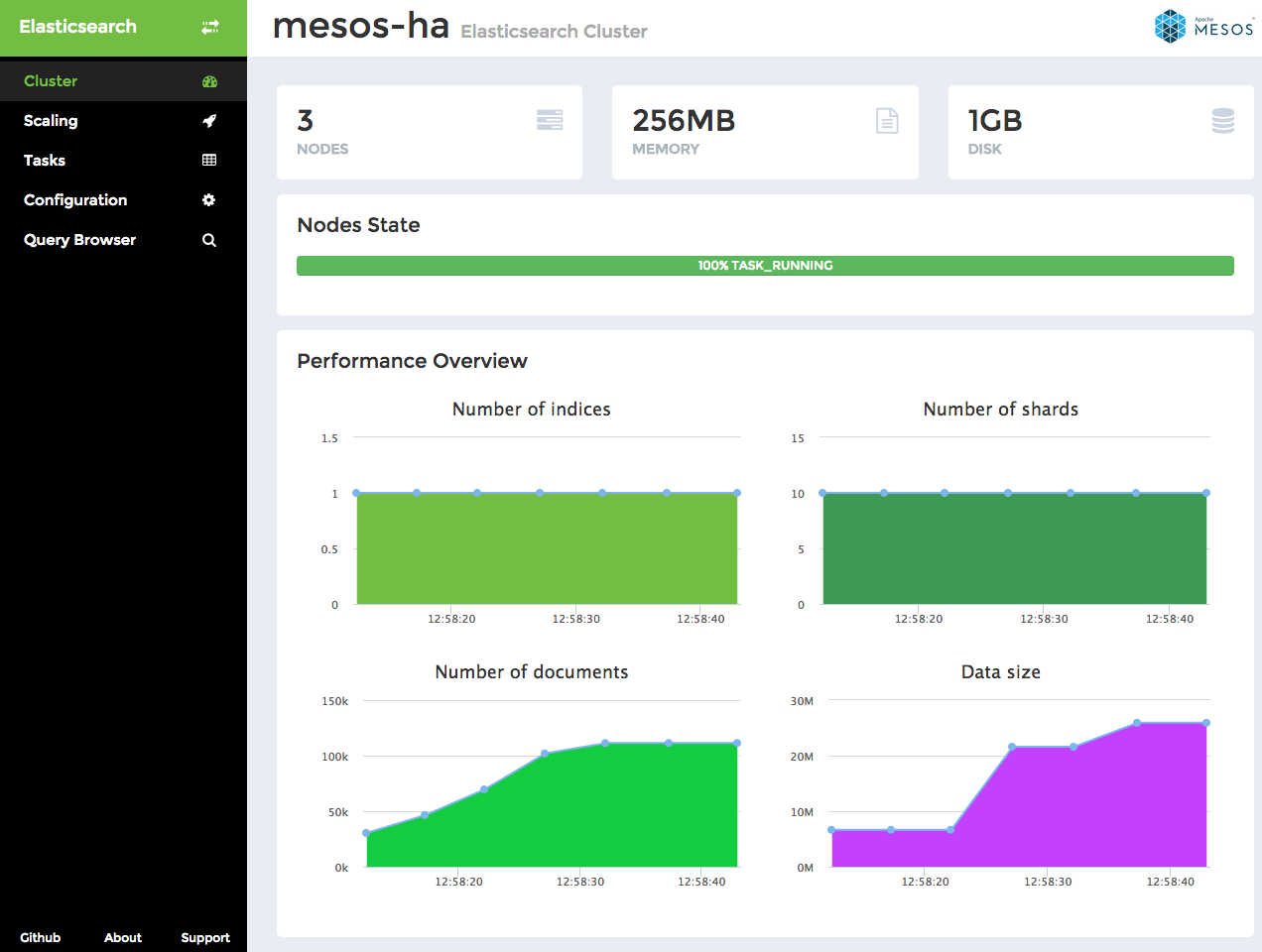
Cluster page shows on the top the number of Elasticsearch nodes in the cluster, the overall amount of RAM and disk space allocated by the cluster. State of individual nodes is displayed in a bar, one color representing each state and the percentage of nodes being in this state.
Below you can see Performance Overview with the following metrics over time: number of indices, number of shards, number of documents in the cluster and the cluster data size.
Scaling
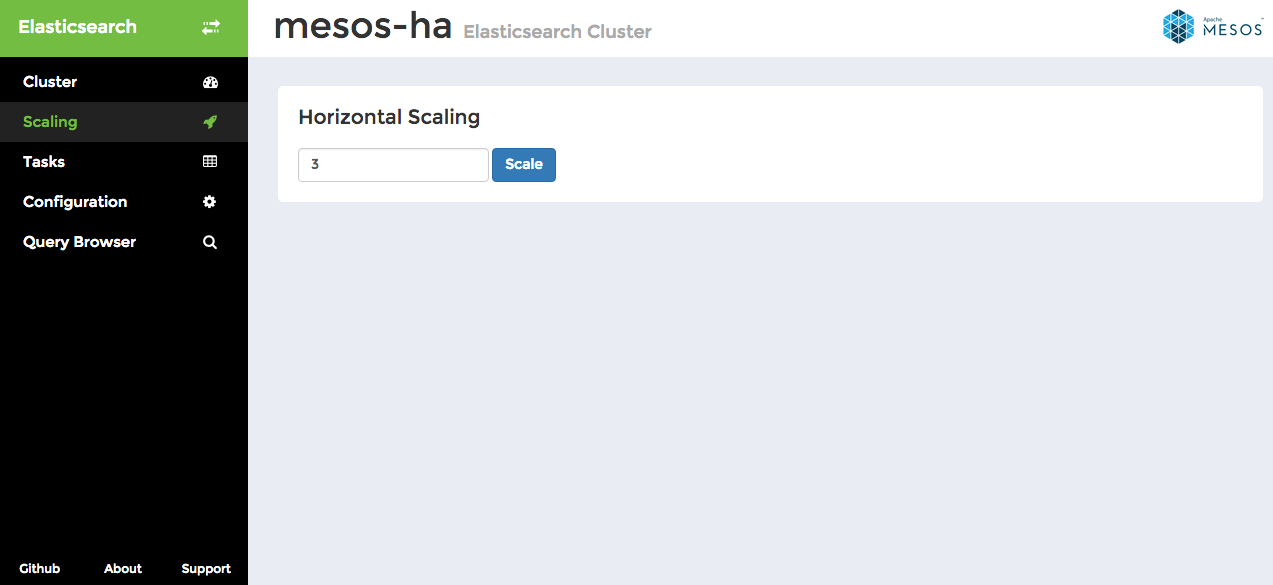
This simple interface allows you to specify a number of nodes to scale to.
Tasks List
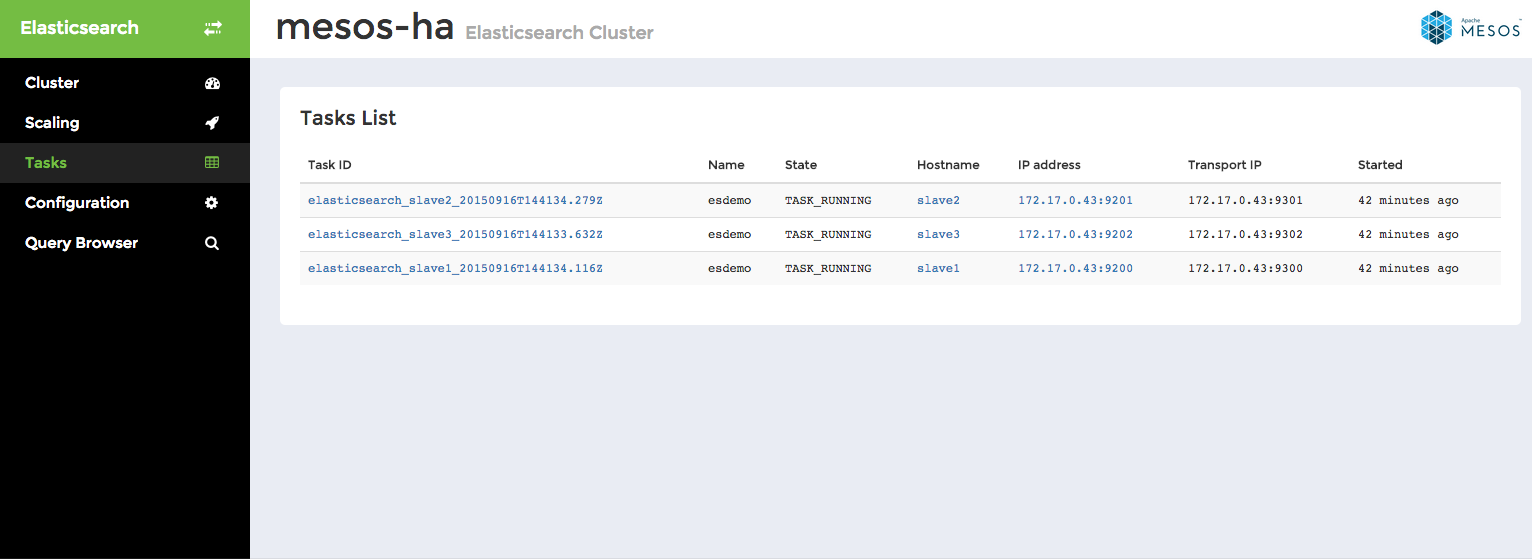
Tasks list displays detailed information about all tasks in the cluster, not only those currently running, but also tasks being staged, finished or failed. Click through individual tasks to get access to Elasticsearch REST API.
Configuration
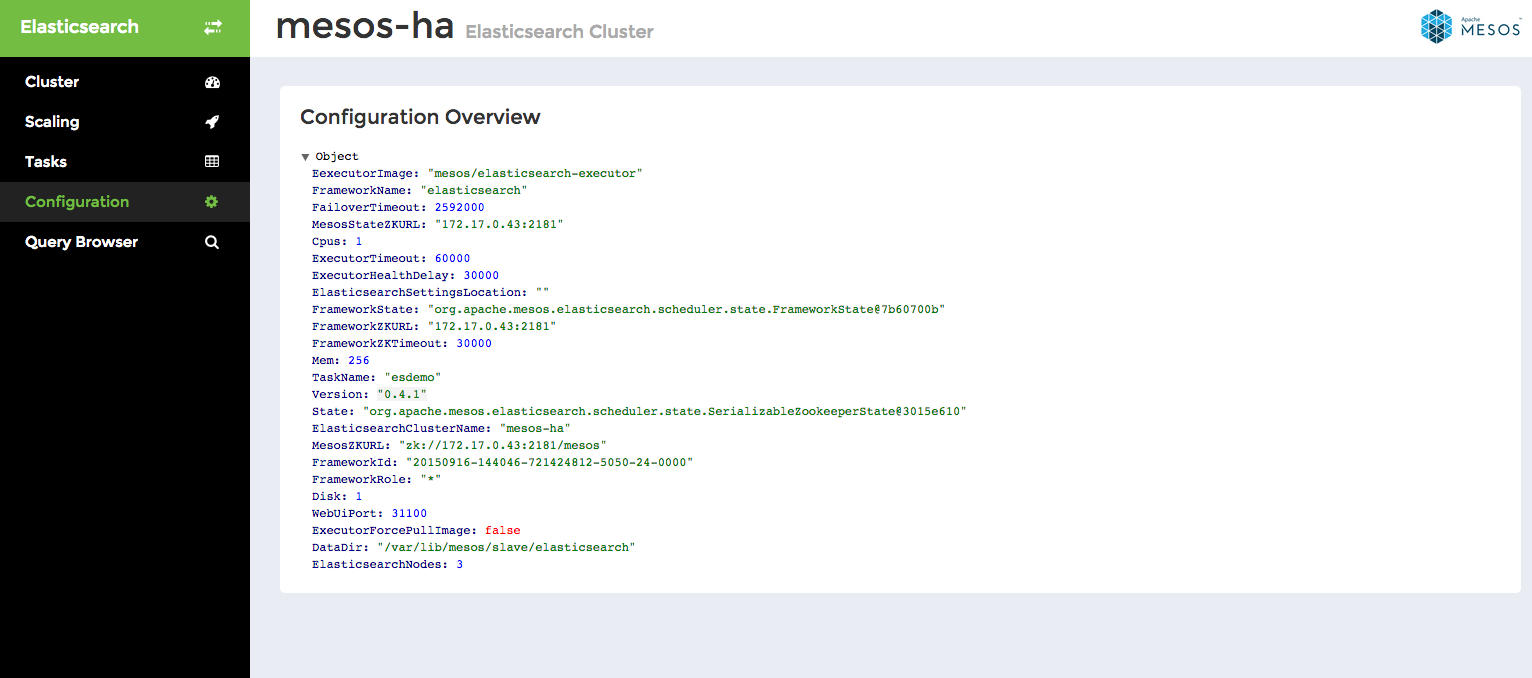
This is a read-only interface displaying an overview of the framework configuration.
Query Browser
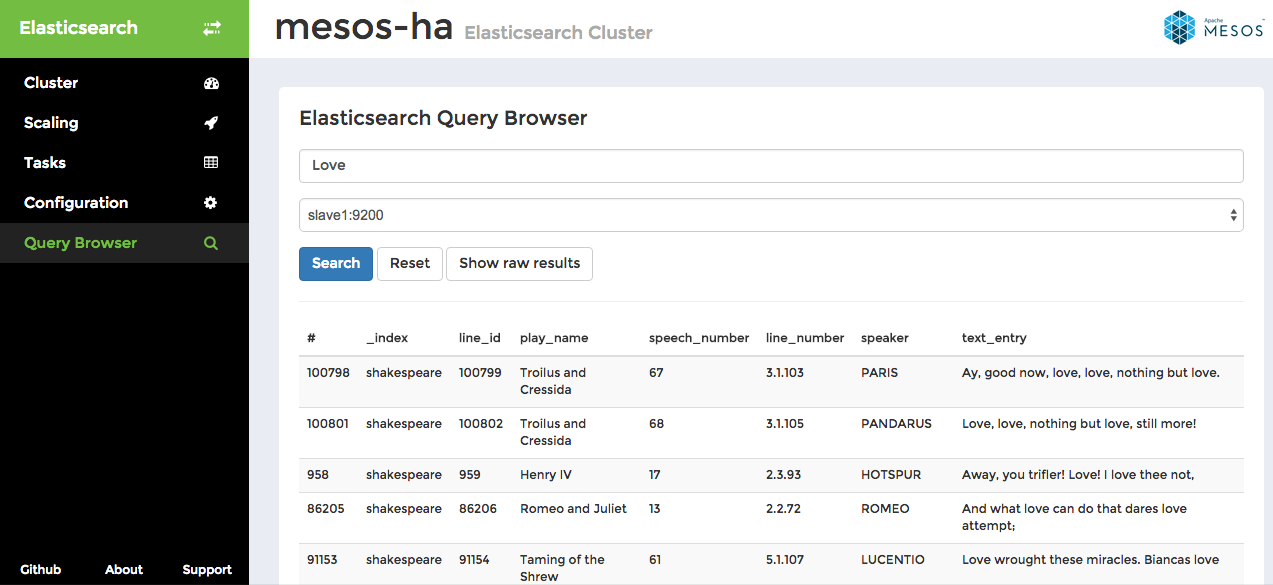
Query Browser allows you to examine data stored on individual Elasticsearch nodes. In this example we searched for the word "Love" on slave1 node. You can toggle between tabular view and raw results view mode, which displays the raw data returned from Elasticsearch /_search API endpoint.
Known issues
- Issue #177: Executors keep running if the scheduler is killed unless the DCOS CLI is used.
Developers Guide
For developers, we have provided a range of tools for testing and running the project. Check out the minimesos project for an in-memory Mesos cluster for integration testing.
Quickstart
You can run Mesos-Elasticsearch using minimesos, a containerized Mesos cluster for testing frameworks.
How to run on Linux
Requirements
- Docker
$ ./gradlew build buildDockerImage system-test:main
How to run on Mac
Requirements
- Docker Machine
$ docker-machine create -d virtualbox --virtualbox-memory 4096 --virtualbox-cpu-count 2 mesos-es
$ eval $(docker-machine env mesos-es)
$ sudo route delete 172.17.0.0/16; sudo route -n add 172.17.0.0/16 $(docker-machine ip mesos-es)
$ ./gradlew build buildDockerImage system-test:main
System test
The project contains a system-test module which tests if the framework interacts correctly with Mesos, using minimesos. We currently test Zookeeper discovery and the Scheduler's API by calling endpoints and verifying the results. As the framework grows we will add more system tests.
How to run system tests on Linux
Requirements
- Docker
Run all system tests
$ ./gradlew build buildDockerImage system-test:systemTest
Run a single system test
$ ./gradlew -DsystemTest.single=DiscoverySystemTest system-test:systemTest
How to release
- First update the CHANGELOG.md by listing fixed issues and bugs
- Update the version number in the Configuration.class so that the Web UI shows the correct version number.
- Push changes
- Verify that the Continuous Build Pipeline completes successfully.
- Run the Release Build and pick a release type: patch, minor or major.
- Done!
Support
Get in touch with the Elasticsearch Mesos framework developers via mesos-es@container-solutions.com
Sponsors
This project is sponsored by Cisco Cloud Services
License
Apache License 2.0